8-K (Current Report, SEC Filing)
Data Overview

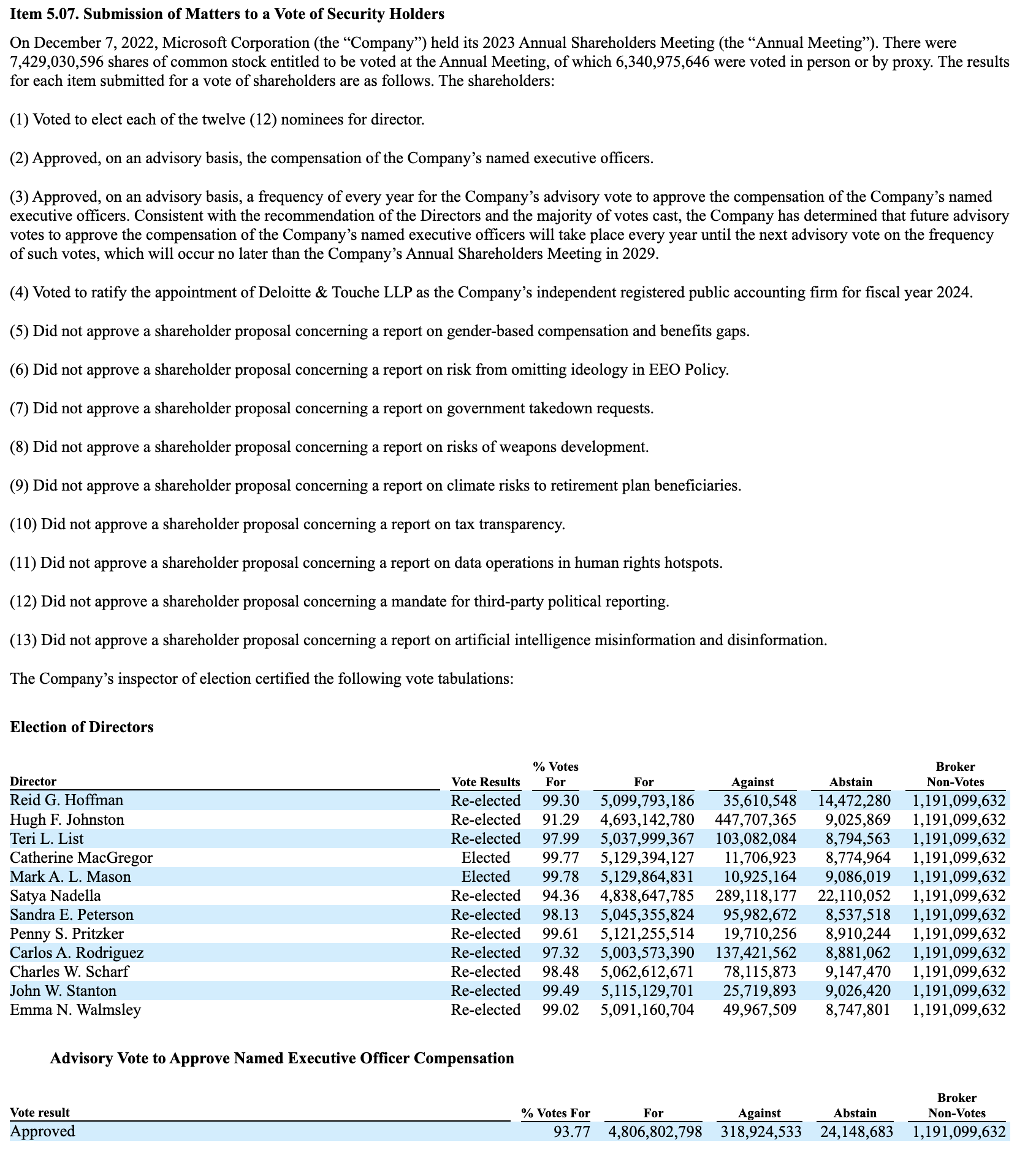
Example of the first 2 pages of an 8-K from Microsoft (Typical 10-Ks range from 2 to 10 pages, shorter compared to 10-Qs and 10-Ks depending on the number of Items included (e.g., Item 2.02 Earnings, Item 1.01 Agreements), whether exhibits (like earnings slides or press releases) are embedded or linked, whether the filing includes XBRL-tagged financials (e.g., Item 9.01))
Form 8-K, often called the “current report”, is the SEC’s real-time disclosure mechanism for U.S. public companies. Whenever a material corporate event occurs (e.g., a major acquisition, CEO departure, cybersecurity incident), issuers must file an 8-K within four business days to level the informational playing field between insiders and the market. The form was overhauled in 2004 to expand its item list and accelerate the deadline, firmly embedding it as the market’s first look at unscheduled, price-sensitive developments. Effectively mined, Form 8-K data supplies very fresh, event-driven signals that complement slower fundamental factors, crucial for high-frequency arbitrage strategies when processed through robust, low-latency NLP and feature-engineering pipelines.
Relevance for predictive modeling
event-driven; mandatory ≤4 business-days after any material corporate development. Item codes like 2.02 (earnings), 4.02 (restatements) and 1.05 (cyber-incident) carry the largest abnormal-return signatures. Intraday alpha half-life can be < 90 minutes, so low-latency parsing is critical.
Document anatomy & formats
Item-coded sections: The report is partitioned into topical “Items” under six sections (1–6) plus Reg FD (7) and Other Events (8). The full list is defined in the SEC template. Examples:
Item 1.05 — Cybersecurity Incident
Item 2.02 — Results of Operations and Financial Condition
Item 4.02 — Non-Reliance on Previously Issued Financial Statements
Item 5.02 — Departure of Directors or Principal Officers
File formats: EDGAR disseminates HTML plus submission text; many filings also carry inline-XBRL for numeric exhibits. Vendors (e.g., S&P Global Machine-Readable Filings) stream parsed JSON/XML packages.
Data volume: A single 8-K averages 5–25 kB of text; an S&P 1500 universe produces ~60 GB/year (HTML) and >100 GB with attachments.
Latency:
Fast pipes are critical: many item-level abnormal-return studies find sizable price moves in the first trading hour.
Company event → SEC filing ≤ 4 business days (mandatory)
Posting on sec.gov 1–3 min after EDGAR acceptance
EDGAR JSON API update “Real-time… < 1 s processing delay”
Vendor alert feeds StreetAccount headline < 60 s; S&P parsed JSON 10–20 min (internal SLA)
Data Processing Pipeline
This is an overview of what the pipeline could look like as part of a first-draft requirements sheet. Teams should refine based on tech stack and custom needs.
Ingest the Filing
The system continuously monitors for new 8-Ks:Poll the EDGAR RSS feed and SEC API every 15 seconds to detect fresh filings.
Also receive push updates from data vendors via Kafka streams.
Each filing is versioned and logged with a timestamp to maintain auditability.
Parse the Content
Once a filing is received, the raw HTML is parsed:Use BeautifulSoup to extract structure and text.
Automatically detect and classify Item codes (e.g., Item 2.02 for results).
Extract inline XBRL if present for numerical disclosures.
Clean and Segment the Filing
The next step is to isolate the relevant sections:Remove generic boilerplate text and legal disclaimers.
Identify and extract the body of each Item and any accompanying exhibits.
Apply NLP and LLM Annotation
Enrich the text with machine learning–based insights:Apply FinBERT to score sentiment on a per-item basis.
Generate topic vectors using BERTopic for clustering or retrieval tasks.
Perform named-entity recognition to tag companies, products, legal terms, and executives.
Manual Quality Assurance (0.2%)
A small random sample is inspected to ensure accuracy:Confirm correct Item tagging and proper handling of large tables or attachments.
Publish to Feature Store
The final structured output is stored for modeling:Create point-in-time feature snapshots, indexed by
tickerandfiling_datetime.
Features for Predictive Modeling
-
{
"ticker": "MSFT",
"filing_datetime": "2023-05-10T16:05:07-04:00",
"filing_date": "2023-05-10",
"after_hours_flag": true,
"regfd_only_flag": false,
"item_codes": ["2.02", "7.01", "9.01"],
"item_count": 3,
"text_metrics": {
"length_words": 1875,
"avg_sentence_length": 16.4,
"exhibit_count": 3,
"lexical_novelty_cosine": 0.31,
"jaccard_similarity_vs_prior": 0.76,
"unique_word_count": 856,
"readability_score_flesch": 42.1,
"keyword_density": {
"guidance": 0.014,
"revenue": 0.019,
"inflation": 0.003
}
},
"sentiment_scores": {
"headline_sentiment": 0.23,
"body_sentiment": -0.04,
"subjectivity": 0.19,
"sentiment_zscore_vs_sector": -1.23,
"sentiment_change_vs_prior_8k": -0.12
},
"item_specific_features": {
"2.02_eps_surprise_pct": 6.2,
"2.02_revenue_surprise_pct": 3.1,
"2.02_guidance_delta_pct": -3.5,
"2.02_guidance_type": "lowered",
"4.02_non_reliance_flag": 0,
"7.01_new_product_mention_flag": 1,
"7.01_mna_mention_flag": 0,
"9.01_exhibits_included": true
},
"semantic_topics": {
"ai": 0.61,
"macroeconomy": 0.12,
"cybersecurity": 0.08,
"supply_chain": 0.03,
"restructuring": 0.00
},
"named_entities_mentioned": {
"executives": ["Satya Nadella"],
"product_names": ["Azure AI", "Copilot"],
"competitor_tickers": ["GOOGL", "AMZN"]
},
"timing_metadata": {
"time_to_file_after_close_minutes": 75,
"is_emergency_filing": false,
"modification_count": 0,
"days_since_last_8k": 17
}
}
Field Definitions and Explanations
1. Filing Metadata
ticker: Public company ticker symbol.
filing_datetime: Timestamp of 8-K release on EDGAR.
filing_date: Date part of the timestamp.
after_hours_flag: Was the filing posted after regular market hours?
regfd_only_flag: If true, signals a Regulation FD-only disclosure, often less material.
2. Item Code Information
item_codes: List of SEC-defined 8-K sections (e.g., 2.02 for earnings, 7.01 for business updates).
item_count: Count of individual items disclosed (feature for length signal).
3. Text Metrics (text_metrics)
length_words: Total word count.
avg_sentence_length: Average number of words per sentence.
exhibit_count: Number of exhibits attached.
lexical_novelty_cosine: Cosine distance compared to prior 8-K.
jaccard_similarity_vs_prior: Jaccard overlap score of unique terms vs. previous filing.
unique_word_count: Measures vocabulary size and complexity.
readability_score_flesch: Readability score (lower = more complex).
keyword_density: Term frequency of business-critical words such as "guidance," "inflation," etc.
4. Sentiment Features (sentiment_scores)
headline_sentiment: Sentiment polarity of the title (e.g., -1.0 to 1.0).
body_sentiment: Full-text sentiment score.
subjectivity: Probability of subjective vs. objective tone.
sentiment_zscore_vs_sector: How unusual is the tone relative to recent sector filings.
sentiment_change_vs_prior_8k: Drift in sentiment compared to prior filing by same company.
5. Item-Specific Financial Disclosures (item_specific_features)
2.02_eps_surprise_pct: Reported EPS vs. consensus (% surprise).
2.02_revenue_surprise_pct: Revenue vs. expectations.
2.02_guidance_delta_pct: Forward EPS or revenue guidance change (%).
2.02_guidance_type: Pulled from NLP classification (e.g., “raised,” “lowered,” “maintained”).
4.02_non_reliance_flag: 1 = management has disavowed prior results.
7.01_new_product_mention_flag: Binary NLP-extracted feature.
7.01_mna_mention_flag: Binary if M&A activity is disclosed.
9.01_exhibits_included: Filing includes presentations, slides, reports, etc.
6. Topic Modeling Features (semantic_topics)
Helps map the 8-K’s framing to current macro/micro market narratives.Probabilistic weights (e.g., via LDA, BERT, BERTopic) on contextual themes:
ai: Artificial intelligence mentions.
macroeconomy, cybersecurity, supply_chain, etc.
7. Named Entity Recognition (named_entities_mentioned)
Useful for building themes around sector linkages or sentiment contagion.
executives: Named officers (e.g., CEO, CFO). Signifies importance.
product_names: NLP-derived mentions of strategic brand/product.
competitor_tickers: Mentions of peer companies (tickers).
8. Timing & Temporal Metadata (timing_metadata)
time_to_file_after_close_minutes: Minutes from 4:00 PM ET to filing time.
is_emergency_filing: Boolean—flagged via legal language or SEC timestamps.
modification_count: How many times this 8-K was revised/resubmitted.
days_since_last_8k: Time delta from previous 8-K by same firm.
Alpha Hypotheses
These are research-backed insights showing how patterns in Form 8-K filings can help predict short-term stock movements:
H1: Different Items Drive Different Reactions
Not all 8-K filings move the market equally. For example, Item 4.02 filings (non-reliance on prior financials) cause strong negative reactions—about –1% the next day and –2% over 20 days.
▸ SEC-API Research on Item 4.02H2: Negative Earnings Language Matters
When Item 2.02 (earnings) contains negative sentiment based on FinBERT scoring, the stock tends to drift downward by about –0.4% overnight.
▸ NYU Stern Paper – Earnings 8-KsH3: Late Filers Signal Trouble
Companies that wait until the last allowable day (Day 4) to file tend to underperform compared to same-day filers—by about 35 basis points over the next 5 days. This supports the idea of a “bad news delay.”
▸ Same NYU SourceH4: Filing Frequency Signals Volatility
Firms that issue four or more 8-Ks in a quarter tend to have higher volatility the following quarter. This supports long-volatility dispersion strategies, as shown by Lerman & Livnat.
▸ Same NYU SourceH5: After-Hours Patterns Matter
Nearly two-thirds of adverse Item 4.02 filings are submitted after 4 p.m., suggesting that bad news is often released when markets are closed. Trading based on this timing pattern can improve execution.
▸ SEC-API Study – After-Hours Effects
Risks and Mitigation
These signals may correlate with common equity factors like size, value, or momentum, so they should be used with awareness of potential overlap.
When building trading signals from 8-K data, there are several challenges—here’s how to address them:
Noisy Reg FD (Item 7.01) Filings
These filings often contain generic or non-material information that dilutes signal strength.
▸ Solution: Add a flag for "Reg FD only" filings and reduce or exclude their weight in your models.Boilerplate Exhibits Inflate Word Counts
Attachments like PDF exhibits can distort word-based metrics.
▸ Solution: Exclude exhibit text unless it’s required for specific items (e.g., Item 9.01 for financial statements).Vendor Item Mis-Tags
Different vendors may tag Items inconsistently, leading to data quality issues.
▸ Solution: Use majority-vote logic across vendors and fall back to regular expression checks on section headers.Simultaneous Press Releases Leak Information
Companies often release news to the press before it hits EDGAR, leading to early market reactions.
▸ Solution: Compare EDGAR timestamps to press wires and flag potential leaks as a feature.Earnings Alpha Crowding (Item 2.02)
Many quant desks already trade on earnings-related sentiment, reducing edge.
▸ Solution: Focus on underused items like 4.02 (restatements) or 1.05 (material events) and enhance with options-based signals like skew.Time Zone Confusion and After-Hours Events
Market reaction windows can shift based on filing time and timezone.
▸ Solution: Standardize all times to Eastern Time (ET) and split analysis into T-0 overnight vs T-1 intraday return buckets.